Transforming Batch Scripts to Streaming with Apache Beam
Written on
Introduction to Apache Beam
Is it feasible to convert a batch processing script to a streaming one without complications? Absolutely! With Apache Beam, this transformation is quite straightforward.
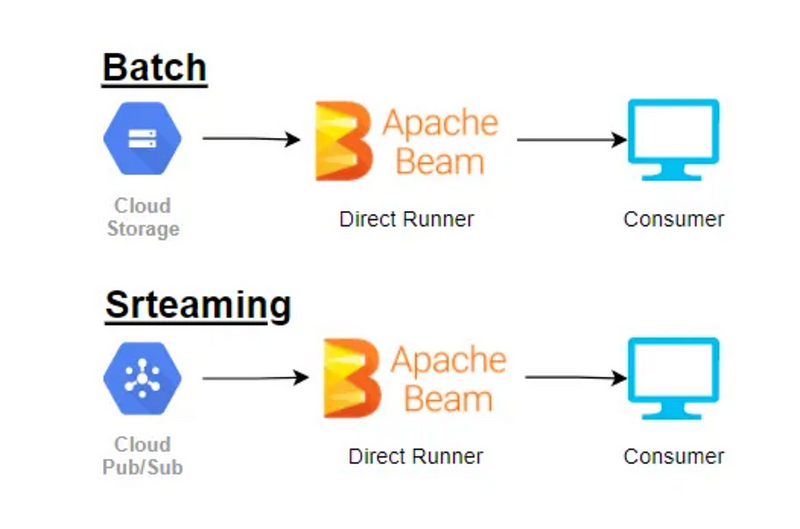
Data Pipeline Basics
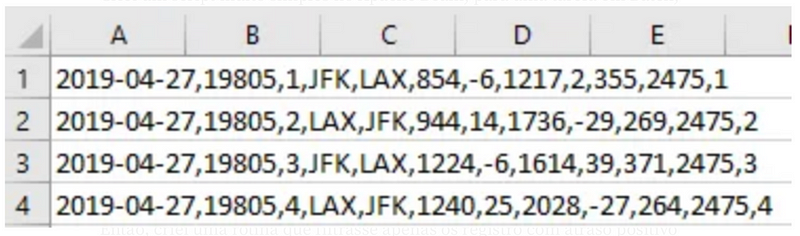
To kick things off, I crafted a basic script using Apache Beam’s Direct Runner, enabling local execution rather than on a Spark or Dataflow engine. The dataset utilized consists of flight information, encompassing details such as flight number, origin, destination, and delays in both departure and arrival.
Filtering Flight Data
I developed a routine that filters records with a positive arrival delay from column 8 (starting at index 0) and retrieves the associated airport information from column 4. The script is as follows:
# Sample script code here
Let’s break down the script:
- Lines 5 and 6: Establish the pipeline as P1.
- Lines 8 and 9: Set the key.json file for Google authentication.
- Line 13: Import the bucket file into Google Cloud Platform (GCP).
- Line 14: Split the records by commas.
- Line 15: Filter for delays greater than 0 in column 8.
- Line 16: Select relevant columns for flight ID and delay.
- Line 17: Output the results.
Sounds simple, right? But what if I need to view this data in real-time?
Transitioning to Real-Time Data
To achieve real-time insights, I implemented a Python routine that sends data lines to PubSub at regular intervals. (Details on this process will not be covered here.) Consequently, I modified the script for streaming:
# Adjusted script code here
Here’s what I changed:
- ADDED Line 6: This indicates the pipeline is now for streaming.
- CHANGED Line 14: The data source transitioned from a GCP bucket file to a PubSub subscription for real-time message handling.
- CHANGED Line 15: I decoded PubSub messages before splitting since they are transmitted in bytes.
- ADDED Line 22: I adjusted the pipeline to run continuously rather than just once.
And that’s it!
While the example is straightforward, it illustrates the differences between executing a script in Apache Beam for batch processing and streaming using the Direct Runner.
Further Learning Resources
If you're keen to dive deeper, I offer an introductory course on this technology on Udemy. Note that the English version does not cover streaming due to technical issues.
Links to Courses:
Additional Insights for Data Engineers
Key concepts every Data Engineer should be familiar with include:
- Data Modeling, CDC, Idempotency, ETL vs. ELT, Kappa vs. Lambda Architectures, Slowly Changing Dimensions (SCD), and more.
Software Engineering with Python:
- Foundations, Modules, Classes, and Maintainability.
Efficiency in Python:
- Starting with the Basics, Tools for Code Evaluation, Performance Enhancement, and Pandas Optimization.

You can access and enroll in the courses here.
Chapter 1: Introduction to Streaming with Apache Beam
This video titled "How to Write Batch or Streaming Data Pipelines with Apache Beam in 15 mins with James Malone" provides a concise guide to creating data pipelines.
Chapter 2: Unified Batch and Streaming Pipelines
In this video, "How to build unified Batch & Streaming Pipelines with Apache Beam and Dataflow," you'll learn how to effectively manage both types of data processing.