Unlocking the Power of Local LLMs: A Comprehensive Guide
Written on
Chapter 1: Introduction to Local LLMs
Meta has unveiled Llama 2, a significant large language model (LLM) that is free for both research and commercial applications. This release is anticipated to ignite a new era of local LLMs, which can be customized based on this model.
The open-source community has been fervently working on developing locally accessible LLMs as alternatives to ChatGPT since the launch of the initial Llama in late February. Having closely monitored this movement, I have experimented with numerous local LLMs that can operate on standard commercial hardware. My hope is to see a future where individuals can utilize their own personal LLM assistants, free from the limitations imposed by central providers. For businesses relying on LLMs, these models present more private, secure, and customizable options.
In this article, I will share insights I've gathered regarding local LLMs, including the top choices available, instructions for running them, and guidance on selecting the ideal configuration for your needs. I will cover everything necessary to get a model up and running, regardless of your programming experience. Additionally, I'll provide links to pre-configured Google Colab WebUIs for you to explore.
If your main interest lies in experimenting with these models, you can check this repository containing the WebUI Colab Notebooks.
Why Choose Local LLMs?
If you're new to local LLMs, you might be asking, "Why bother when ChatGPT is so powerful?" Initially, I too had doubts about local alternatives. However, after engaging with ChatGPT and other hosted LLMs such as Anthropic's Claude and Google's Bard, I recognized that local LLMs provide distinct advantages—data privacy, security, offline functionality, and greater customization. These factors are crucial when utilizing LLMs.
For those concerned with privacy, or businesses that cater to privacy-conscious clients, sending data to OpenAI or other providers may not be prudent. By operating local LLMs on your own hardware, you retain full control over your data.
Additionally, if you face unreliable internet connectivity or reside in regions where services like OpenAI, Claude, or Google are restricted, a local LLM can serve as an effective offline alternative, allowing for AI assistance wherever you are.
Local LLMs also allow for more flexible and uncensored usage than their hosted counterparts, providing much greater customization in responses.
While models like ChatGPT or Claude are undeniably robust, local LLMs shine in situations such as these. From my testing, I've found several local models to be impressively capable.
Understanding Common Model Formats
A popular platform for sharing local large language models is HuggingFace, which began as a site focused on transformer-based models but has since expanded to various AI frameworks. The transformer architecture underpins both ChatGPT and many open-source local LLMs.
Navigating through the diverse model formats available can be overwhelming. Below are some of the most common formats and when to use them:
- PyTorch (pt): Models in this format typically feature "pytorch" in their file names. PyTorch is an open-source framework for constructing and training neural networks. Many of these models are original transformer-based LLMs. You'll notice some models labeled with "fp16" or "fp32," indicating their precision levels—lower precision reduces memory use, making them more feasible for consumer hardware.
- GGML: Developed by Georgi Gerganov, this format facilitates model execution on CPUs and RAM. GGML employs quantization techniques to minimize model size and resource requirements, enabling operation on standard consumer hardware. The latest version, GGMLv3, supports CPU and GPU.
- GPTQ: This format is a quantization method for generative pre-trained transformers, often recognized by the ".safetensors" extension. Typically, GPTQ models are 4-bit quantized, allowing for rapid inference speeds when run on GPU.
As the LLM landscape evolves, other formats like ONNX are emerging. The general guideline I follow is to choose GPTQ if my GPU can fully accommodate the model, as it provides the fastest inference. If I must rely on CPU, I opt for GGML with Q5_K_M for a balance between speed and quality.
Model Loaders, Bindings, and User Interfaces
Once you've selected a model, you'll need a method to load and run it—often referred to as performing inference. Here are common options for both programmers and non-technical users:
- For GPTQ models, popular options include GPTQ-for-LLaMa, AutoGPTQ, and ExLlama/ExLlama-HF, with ExLlama offering the fastest inference speed for GPUs with sufficient VRAM.
- For GGML models, llama.cpp is the go-to choice, with various UIs built upon this framework, enabling rapid inference even on consumer devices. Programming bindings are available for languages like Python, Node.js, and Go.
For those unfamiliar with coding, choosing a user-friendly UI can simplify the process. Notable examples include:
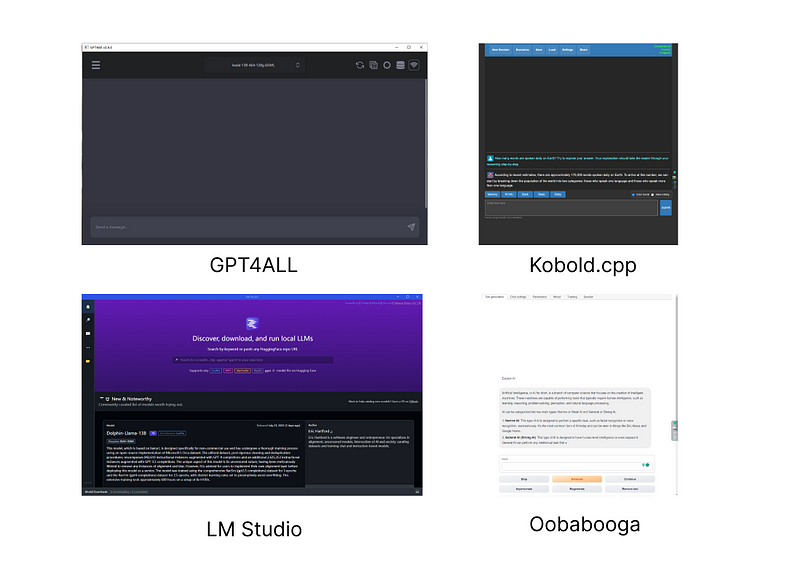
- GPT4All: A UI for GGML models compatible with Windows, MacOS, and Linux.
- Kobold.cpp: A writing-focused UI based on llama.cpp.
- LM Studio: Discover, download, and run local GGML LLMs easily.
- Oobabooga's Text Generation WebUI: A versatile platform for both GPTQ and GGML models, offering extensive configuration options.
Fine-tuning Model Output
Now that you’ve selected your model and tools, you may be surprised at the level of customization available with local LLMs. This flexibility allows you to tailor the model to suit your specific needs.
Key parameters affecting output quality include top-p, top-k, temperature, repetition_penalty, and turn templates.
- Top-p and Top-k govern the vocabulary size used during inference. Top-p selects tokens based on cumulative probability, while top-k chooses the most probable options.
- Temperature adjusts the randomness in the output. Higher temperatures create more diverse responses, while lower temperatures yield more predictable results.
- Repetition penalty indicates how often the model should repeat tokens, and turn templates guide conversational context.
If you're overwhelmed by these settings, user interfaces like Oobabooga provide preset configurations based on popular parameters, making it easier to get started.
Choosing the Right Model for Your Needs
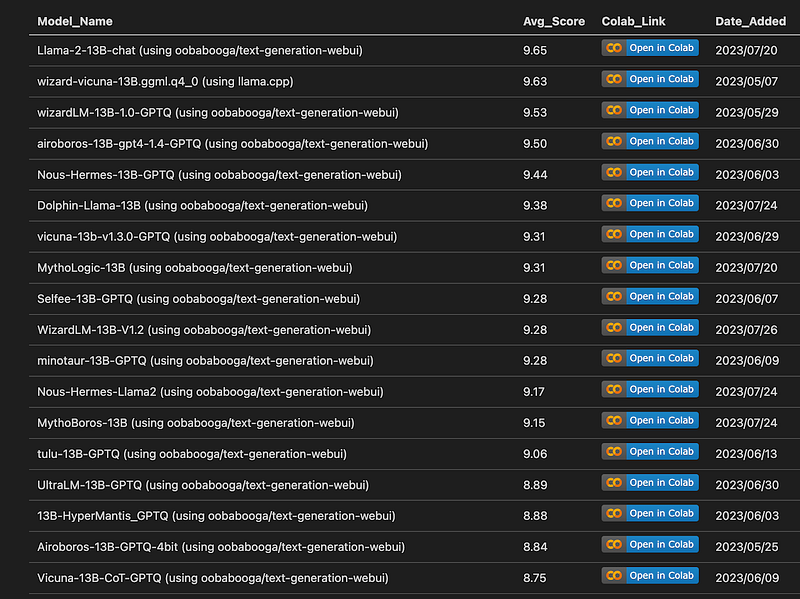
Currently, I recommend Llama-2–13B-chat and WizardLM-13B-1.0 for general use, while the Nous-Hermes-13B is great for unrestricted chat or storytelling. However, I encourage you to experiment with different models to see which suits your needs best.
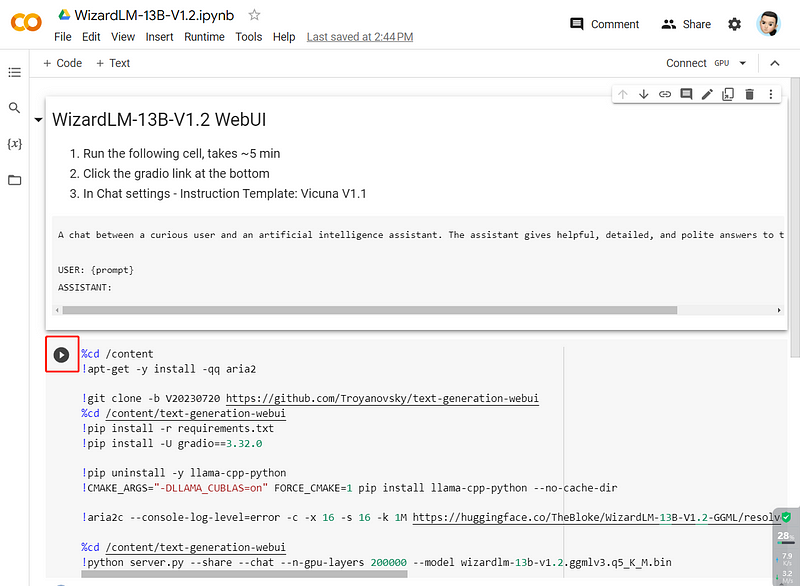
To simplify the testing process, I've created Colab WebUIs for these models, allowing you to leverage Google’s free GPU resources. Just select a model, click “Open in Colab,” run the notebook, and follow the link that appears.
Key Takeaways
By the end of this guide, you should feel equipped to run your own local LLM. Here are the main points to remember:
- Local LLMs offer advantages such as enhanced data privacy, security, and customization compared to hosted services like ChatGPT and Claude.
- Common model formats include PyTorch, GGML, GPTQ, and ONNX.
- Various bindings and UIs make it easy to explore local LLMs, including GPT4All, Oobabooga, and LM Studio.
- Output customization is possible through parameters like top-p, top-k, repetition penalty, and temperature.
- You can experiment with local LLMs using Google Colab WebUI.