The Pursuit of Understanding Amidst the Clamor of Modern Life
Written on
Chapter 1: The Essence of Clarity
In an age marked by seamless global connectivity, we find ourselves surrounded by a myriad of voices. Picture yourself on a busy city street, enveloped by a symphony of sounds—the lively conversations, the steady flow of traffic, and the joyous laughter of children. Now, envision isolating a single voice from this chaos, its clarity piercing through the din. This phenomenon encapsulates the core of the Open Whisper-style Speech Model (OWSM) v3.1. This latest version transcends its predecessors, representing a significant advancement in our quest to decode the complexities of our noisy world.
The Backbone of Babel
At the core of OWSM v3.1 lies the E-Branchformer, an engineering marvel designed to capture the subtleties of spoken language. Imagine a vast network of routes, each one symbolizing a potential interpretation of sound. The E-Branchformer skillfully navigates this intricate maze, adeptly discerning the nuances of speech. It’s akin to giving it a detailed map to the Tower of Babel, enabling it to deftly maneuver through the intricacies of human language.
Section 1.1: Training for the Challenge
Consider training for a marathon—not in terms of distance, but through countless hours immersed in spoken words from all corners of the globe. This is the journey undertaken by OWSM v3.1, propelled by a rich and varied dataset that encompasses numerous languages and dialects. Each element serves as a vital thread in the expansive fabric of human expression, allowing the model to delve deep into the essence of communication, ready to bridge the divide between humans and machines.
Subsection 1.1.1: A Symphony of Diverse Voices
OWSM v3.1 goes beyond mastering a single language; it aims to become a polyglot fluent in the shared language of humanity. Each new language it acquires adds another instrument to its orchestra, enhancing its comprehension and enabling it to create harmonies that were once deemed unattainable. This ambition reflects our innate desire to connect, dismantling barriers to foster a more united world.

Chapter 2: Looking to the Future
As we embark on this exciting new chapter of technological advancement, we recognize that OWSM v3.1's journey is just beginning. The future stretches out before us, filled with possibilities yet to be explored. This isn't merely about enhancing machines; it's about evolving our collective ability to communicate, comprehend, and connect with one another.
The Power of Silence in a World of Noise with Justin Zorn and Leigh Marz - This video delves into the importance of silence in enhancing our understanding amidst the chaos of modern life.
The Power of E-Branchformer
The E-Branchformer serves as a telescope for speech recognition technology, allowing it to uncover details previously hidden by earlier models. This innovative architecture equips OWSM v3.1 to grasp not only words but also the context surrounding them, much like interpreting the deeper meanings of a classic novel.
Training Through a Wealth of Language
OWSM v3.1's training process resembles preparing for an intellectual decathlon, with each event representing a different language or dialect. By engaging with over 180,000 hours of diverse speech, it assimilates languages, cultures, and the intricate nuances that make human speech so vibrant and multifaceted.
The Power of Silence in A World of Noise w/ Justin Zorn & Leigh Marz (TPS427) - This video further explores the role of silence in fostering deeper understanding amidst the noise of daily life.
Section 2.1: Multilingual Mastery
The ability of this model to adeptly navigate multiple languages is akin to having a universal translator at our disposal, dissolving barriers and weaving a tighter fabric of global communication. It signifies a stride towards a world where language serves as a bridge rather than an obstacle.
Section 2.2: Enhanced Speed and Efficiency
With inference speeds improved by up to 25%, OWSM v3.1 exemplifies a transition from a horse-drawn carriage to a high-speed train in the realm of speech recognition. This efficiency paves the way for real-time, accurate translations to become more readily accessible.
A Commitment to Open Science
The ethos of transparency and open-source collaboration that underpins OWSM v3.1 is like unveiling the doors of a secret laboratory to the global community. It fosters innovation and collective progress in the field of speech recognition, inviting all to partake in this exciting journey toward understanding.
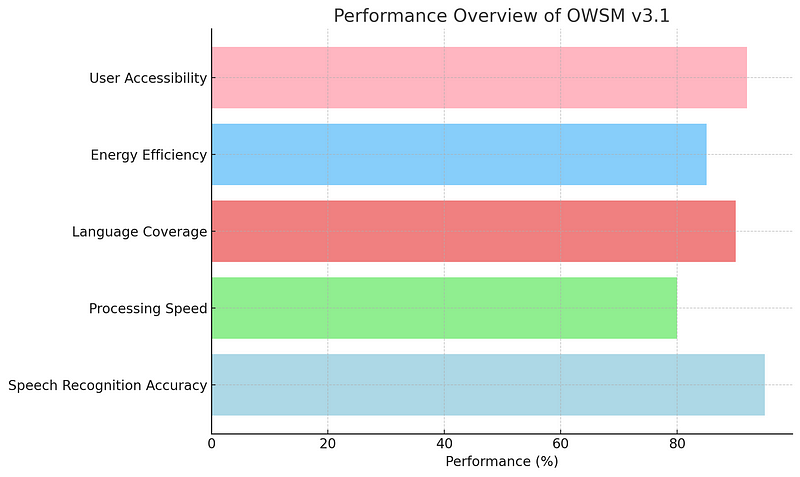
To better grasp the groundbreaking achievements of the Open Whisper-style Speech Model (OWSM) v3.1, let's take a moment to visualize its performance across several critical domains. Below is a graph that succinctly illustrates the model’s capabilities.
A Vision of Hope
As we reflect on the milestones achieved by OWSM v3.1, we witness not just a technological breakthrough but a beacon of hope for our future. This advancement is not only about machines comprehending human speech; it’s about fostering a deeper understanding among people. Through the lens of technology, we envision a world where every voice, regardless of volume, can be heard and appreciated. It’s a future where our linguistic differences enrich rather than divide us, urging us to embark on this journey with open hearts and minds, ready to unlock the untapped potential of our collective voice.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your insight into the future of technology. Subscribe for new videos every Saturday!
Watch us on YouTube